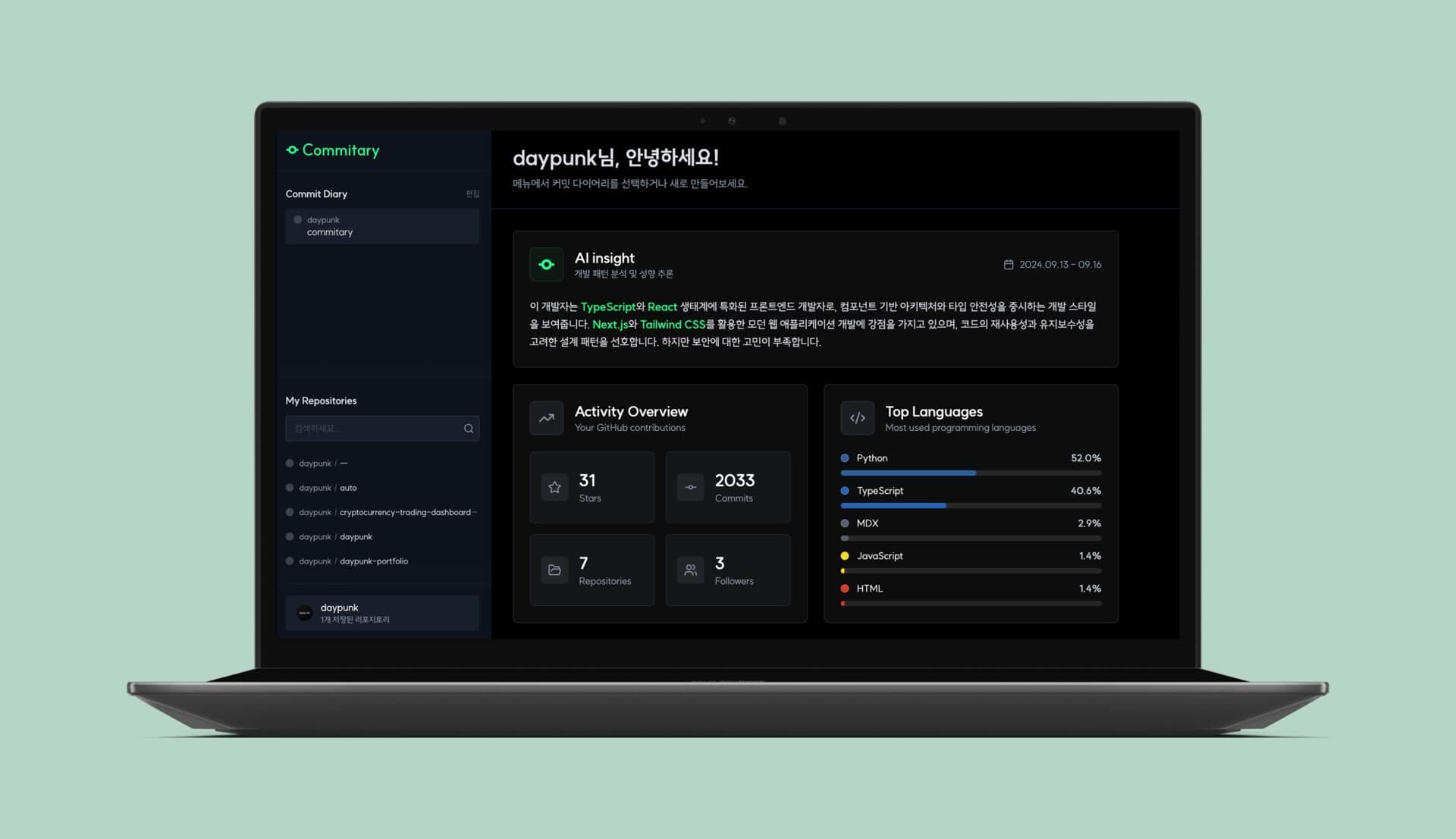
Commitary
커밋과 코드리뷰를 매일의 다이어리로 묶어내는 개발자 도구
Timeline
2025.08
Role
Product Manager, Front-End
Leveraged
서비스 기획, RAG 시스템 설계, UI/UX

Problems & Solution
개발자의 성장과 평가
개발자는 하루 평균 약 2.8회 커밋합니다(GitClear, 2024). 거기엔 의사결정과 사고 과정이 담기지만, 이 데이터는 거의 재사용되지 않습니다. Velog와 Tistory 같은 개발 블로그에서 ‘오늘의 작업’을 기록한 글은 4% 미만이었습니다. 개발자의 실제 성장 과정은 데이터로 남지 않습니다.
그래서 이력서를 쓸 때, 성과 리뷰가 돌아올 때, 채용 평가를 받을 때 개발자는 자기 성장을 재구성하느라 시간을 씁니다. 평가하는 시니어와 HR도 비슷한 비용을 치릅니다. 한국 직장인의 57%는 자신의 인사평가 결과를 신뢰하지 않는다고 답했고(JobKorea, 2024), 그 불신의 한가운데에 “기여를 정확히 보지 못한 평가”가 있습니다. 한 명의 커밋을 만든 사람과 평가하는 사람이, 같은 데이터를 다른 시점에 다시 만드는 비용입니다.
Commitary는 이를 매일 쌓이는 다이어리로 풀었습니다. 개발자가 따로 글을 쓰지 않아도, 그날의 커밋과 코드리뷰가 한 페이지에 자동으로 모입니다. 개발자는 성장을 기록해야 하는 허들에서 벗어나고, 시니어와 HR은 한 눈에 볼 수 있는 insight로 평가합니다. 같은 데이터가 양쪽 시점에서 한 번에 작동합니다.

Code review
PR을 넘어, 개인에게 집중한 코드리뷰
코드리뷰가 개발자의 사고력을 가장 정밀하게 드러낸다고 판단했습니다. 시장에 이미 존재하는 도구들을 살피니, 두 진영으로 갈렸습니다. GitHub 외부에서 OAuth로 동작하는 도구(jules, cubic, CodeRabbit)와 GitHub 내부 PR bot으로 동작하는 도구(Gemini Code Assist, cubic, CodeRabbit, greptile). 두 진영 모두 PR 단위로 코드를 보고, 팀 협업과 배포 효율을 끌어올리는 데 최적화되어 있었습니다.
Commitary는 다른 축에 있습니다. 팀의 머지 속도가 아니라, 한 개발자의 성장 궤적을 추적합니다. PR이 아닌 개인 커밋 단위로 로그를 수집해, 일별 다이어리로 정리합니다. 협업의 산물이었던 리뷰가 자기 성장의 피드백 루프로 변환됩니다.
또 한 가지 관찰. Notion, Linear, Jira처럼 개발자가 일상에서 쓰는 외부 도구는 GitHub와 양방향으로 연결되어 있지만, 그 연결선 위에서 리뷰가 일어나는 도구는 없었습니다. 이 비어 있는 영역이 다음 확장의 지점입니다. 코드리뷰 도구를 넘어 개발자 업무 전반을 잇는 확장형 DX 인프라로 자랄 여지가 있습니다.
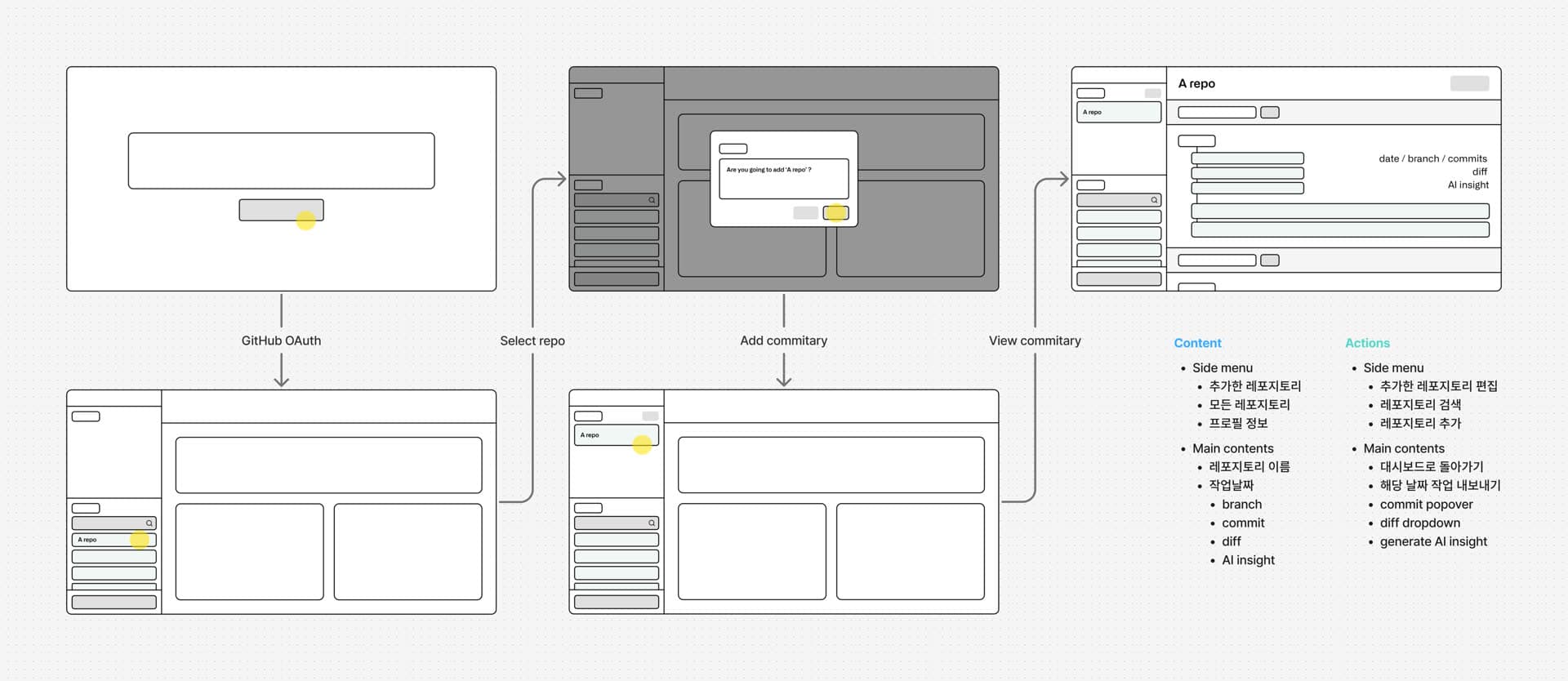
User flow
개발자의 하루가 곧 파이프라인
Commitary는 개발자의 일상 흐름을 바꾸지 않습니다. GitHub OAuth와 분석할 리포지토리 선택, 두 번의 설정으로 끝납니다. 그 이후엔 커밋 → 코드리뷰 → 리포트가 자동으로 이어집니다. 매주 월요일에 리포지토리 스냅샷이 갱신되고(주간 베이스라인이 비용 최적화의 핵심입니다. 자세한 건 뒤 RAG 섹션에서), 일별 커밋은 자연어로 요약되어 다이어리로 쌓입니다. 이렇게 매일 쌓이는 다이어리가 처음의 두 병목, 개발자의 성장 기록 허들과 평가자의 한 눈 병목을 한 번에 풉니다.
GitHub OAuth
GitHub 계정 한 번의 OAuth로 시작합니다. 인증은 Next.js에서, 인증 이후의 GraphQL 요청은 서버에서 안전하게 실행합니다.
리포지토리 연동
GitHub 계정과 연결된 리포지토리 중, 다이어리로 추적할 리포지토리를 선택합니다.
일별 작업 조회
오늘 내가 한 커밋과 변경(diff)을 날짜별로 시각화해 한눈에 확인할 수 있습니다.
AI Insight
AI가 작업을 요약(Summary), 코드 단위 분석(Detail), 피드백(Code Review)의 세 섹션으로 나누어 제공합니다.
오늘 작업 내보내기
오늘의 결과를 Markdown 복사, .md 파일, .json 파일 형태로 내보낼 수 있습니다.
RAG system
코드베이스 임베딩과 MECE 기반 RAG 설계
Commitary는 개발자의 일별 활동을 코드 레벨에서 이해해야 합니다. 변경된 diff만 봐서는 “왜 이 코드를 작성했는가”를 파악할 수 없기 때문에, 전체 리포지토리를 컨텍스트로 활용하는 RAG 시스템을 설계했습니다.
전체 코드베이스를 주 단위로 스냅샷하고, 일별 커밋 변경사항을 쿼리로 사용해 관련 코드를 검색합니다. 작업의 의도와 영향 범위를 시스템 전체 맥락에서 해석할 수 있게 됩니다.
# 각 코드 조각은 6개 차원으로 식별됩니다
metadata = {
"commitary_user": commitary_id, # 누구의 코드인가
"repo_id": repo_id, # 어떤 저장소인가
"target_branch": branch, # 어떤 브랜치인가
"lastModifiedTime": file.last_modified_at, # 언제 시점인가
"filepath": file.path, # 어떤 파일인가
"chunk_id": f"{repo_id}_{branch}_{file.path}_{i}" # 몇 번째 조각인가
}브랜치별 독립 컨텍스트와 MECE 원칙
전체 코드베이스를 컨텍스트로 삼으면 풍부하지만, 여러 브랜치가 동시에 개발되면 교차 참조로 오분석이 생깁니다.
Commitary는 이를 MECE(Mutually Exclusive & Collectively Exhaustive) 원칙으로 풀었습니다. 각 브랜치를 독립된 코드베이스로 취급해, 분석 시 해당 브랜치의 스냅샷만 참조하도록 데이터 레벨에서 격리했습니다.
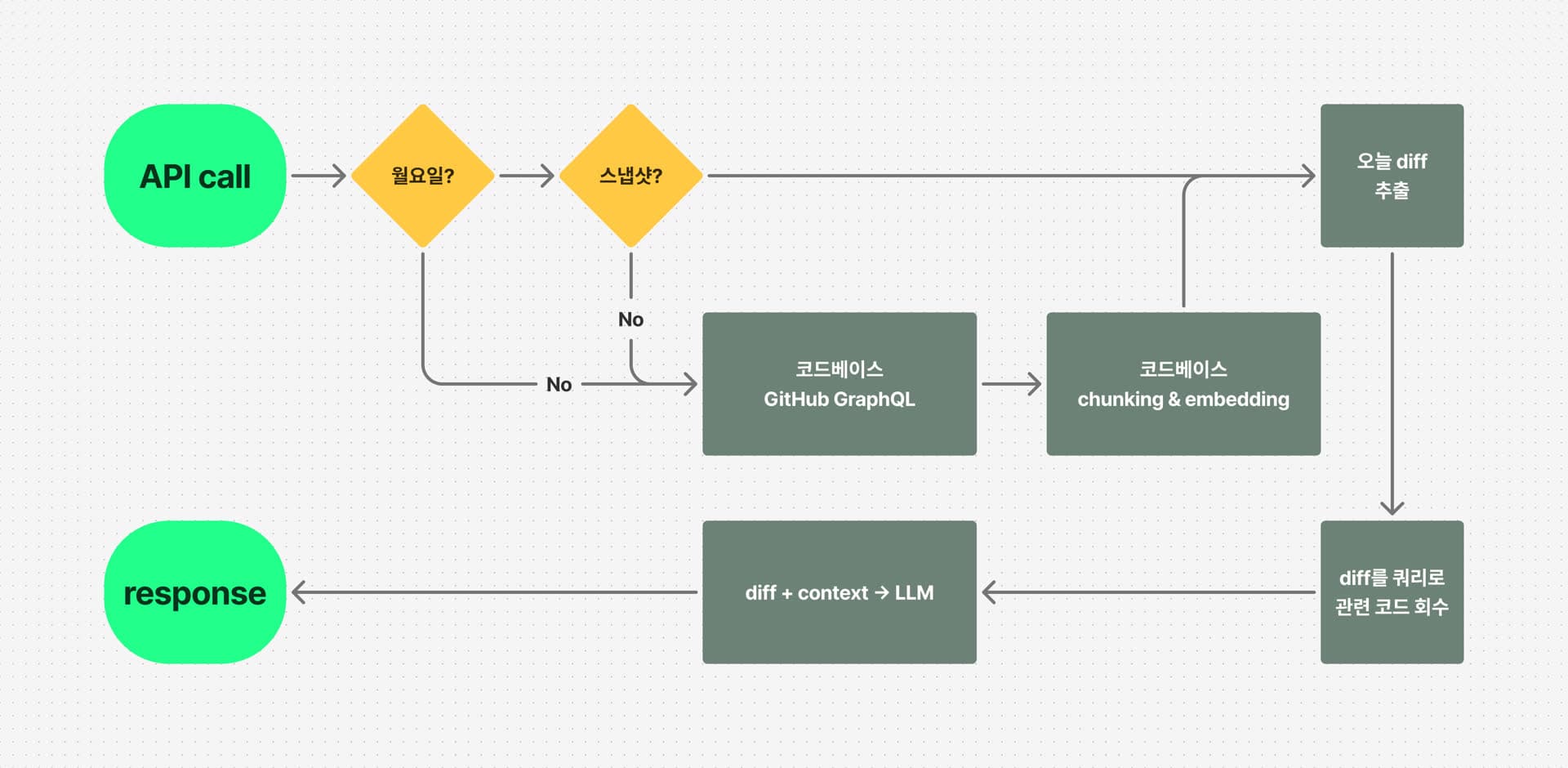
주간 재사용 전략으로 비용 최적화
브랜치별 스냅샷은 그대로 두면 비용이 빠르게 늘어납니다. Commitary는 이를 주간 재사용 + On-Demand 생성 전략으로 풀었습니다.
- 스냅샷 주기를 일 단위에서 주 단위(월요일 기준)로 정규화 → 같은 주의 모든 분석은 동일 베이스라인을 참조
- 존재 여부 사전 검사로 중복 생성 방지
- 사용자가 명시한 브랜치만 분석하여 비활성 브랜치의 불필요한 저장 방지
- LLM 입력 길이 제한(파일 2K, 전체 8K)로 자동 생성 코드나 대규모 리팩토링 비용 제어
# 이미 이번 주 스냅샷이 있는지 확인합니다
monday_date = today - timedelta(days=today.weekday())
cur.execute("""
SELECT 1 FROM vector_data
WHERE repo_id = %s
AND target_branch = %s
AND lastModifiedTime = %s
""", (repo_id, branch, monday_date))
if cur.fetchone():
# 이미 있으면 재사용
snapshot_exists = True중규모 리포지토리(50파일, 10,000줄) 기준 3개 브랜치를 사용할 때
월간 비용 약 40원, 일일 저장 대비 86% 절감입니다.

If I had more time...
다음 실행할 단계
리뷰 응답 구조화
LLM 응답을 JSON으로 파싱해 각 리뷰를 컴포넌트 단위로 분해해 가시성을 높입니다.
시니어와 HR 뷰 확장
개인 데이터 위에 시니어와 HR 관점의 대시보드를 얹어, 개인 기록과 조직 인사이트를 잇습니다.
사용자 검증과 피드백 루프
A/B 테스트로 여정 데이터를 수집하고, 사용자 피드백을 제품 개선 사이클에 통합합니다.